---
title: "Theory"
output:
prettydoc::html_pretty:
theme: tactile
highlight: vignette
vignette: >
%\VignetteIndexEntry{Theory}
%\VignetteEngine{knitr::rmarkdown}
%\VignetteEncoding{UTF-8}
---
```{r, include = FALSE}
knitr::opts_chunk$set(
collapse = TRUE,
comment = "#>"
)
```
This vignette presents a general overview of the _clugen_ algorithm. A complete
description of the algorithm's theoretical framework is available in the article
"[Generating multidimensional clusters with support
lines](https://doi.org/10.1016/j.knosys.2023.110836)" (an open version is
[available on arXiv](https://arxiv.org/abs/2301.10327)).
_Clugen_ is an algorithm for generating multidimensional clusters. Each cluster
is supported by a line segment, the position, orientation and length of which
guide where the respective points are placed. For brevity, *line segments* will
be referred to as *lines*.
Given an $n$-dimensional direction vector $\mathbf{d}$ (and a number of
additional parameters, which will be discussed shortly), the _clugen_ algorithm
works as follows ($^*$ means the algorithm step is stochastic):
1. Normalize $\mathbf{d}$.
2. $^*$Determine cluster sizes.
3. $^*$Determine cluster centers.
4. $^*$Determine lengths of cluster-supporting lines.
5. $^*$Determine angles between $\mathbf{d}$ and cluster-supporting lines.
6. For each cluster:
1. $^*$Determine direction of the cluster-supporting line.
2. $^*$Determine distance of point projections from the center of the
cluster-supporting line.
3. Determine coordinates of point projections on the cluster-supporting line.
4. $^*$Determine points from their projections on the cluster-supporting
line.
Figure 1 provides a stylized overview of the algorithm's steps.
```{asis, echo = crul::ok("https://raw.githubusercontent.com/clugen/.github/main/images/algorithm.png")}
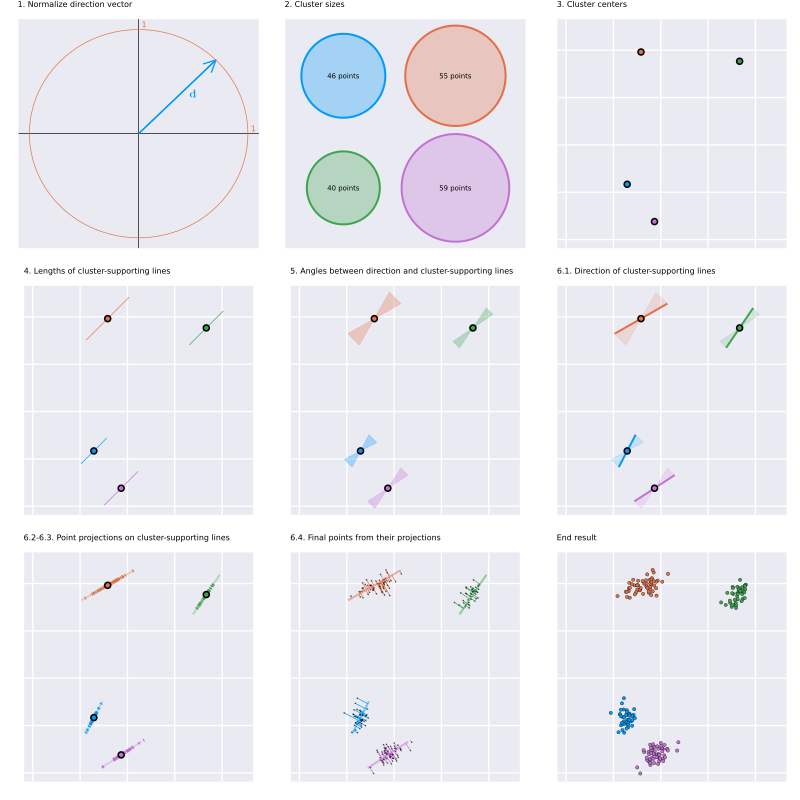
```
The example in Figure 1 was generated with the following parameters:
| Parameter values | Description |
|:----------------- | :------------------------ |
| $n=2$ | Number of dimensions. |
| $c=4$ | Number of clusters. |
| $p=200$ | Total number of points. |
| $\mathbf{d}=\begin{bmatrix}1 & 1\end{bmatrix}^T$ | Average direction. |
| $\theta_\sigma=\pi/16\approx{}11.25^{\circ}$ | Angle dispersion. |
| $\mathbf{s}=\begin{bmatrix}10 & 10\end{bmatrix}^T$ | Average cluster separation. |
| $l=10$ | Average line length. |
| $l_\sigma=1.5$ | Line length dispersion. |
| $f_\sigma=1$ | Cluster lateral dispersion. |
Additionally, all optional parameters (not listed above) were left to their
default values. The complete list of parameters is presented in the `clugen()`
function documentation.